
type
status
date
summary
slug
tags
category
password
icon
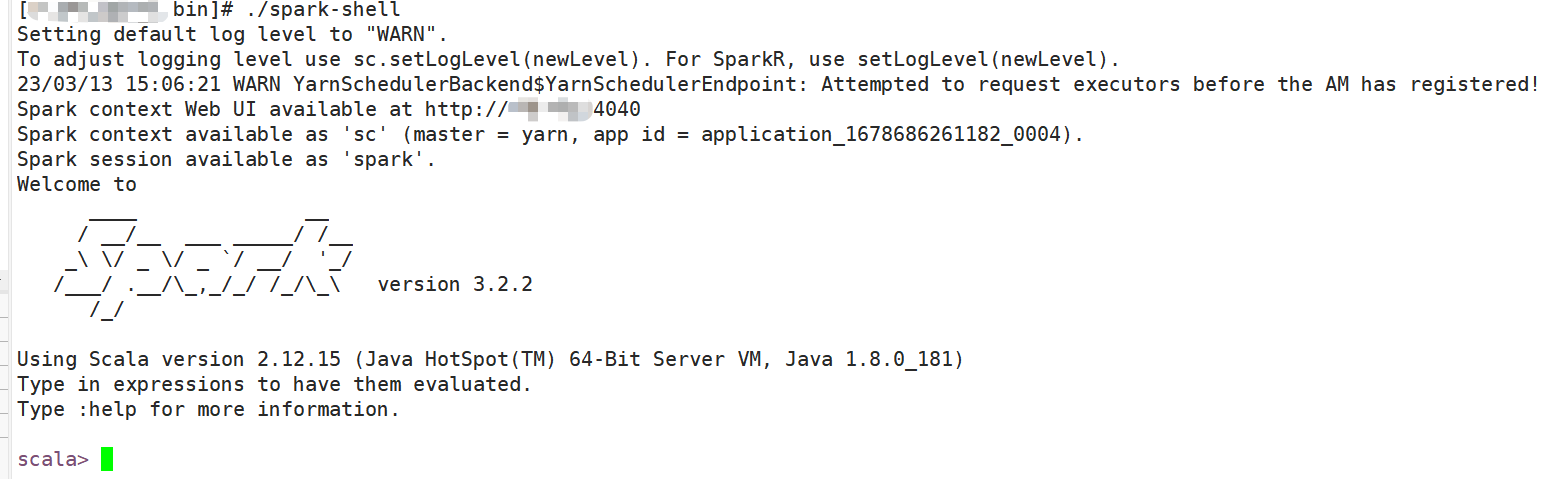
CDH 6.3.2 升级 Spark 3
由于
CDH6.3.2版本以上已不开源,目前常用组件只能自编译升级,比如 Spark 。看网上的资料,有人说 Spark3 的 SQL 运行性能比 Spark2 可提升 20%,本人未验证,但是 Spark3 的 AE 功能的确很香,能自适应解决 Spark SQL 的数据倾斜。
准备工作
- 环境及软件版本
- jdk-1.8.0_181
- maven-3.8.4
- scala-2.12.15
- spark-3.3.0
说明:maven 和 scala 请不要改变小版本,如果要改变,请改动 pom 中相应的版本号,否则编译时会有版本错误
- 下载
tar包
- 解压
- 移至
/opt /mod/目录
- 设置
jdk、scala、maven的环境变量
添加如下内容
- 应用
编译 Spark3
修改
spark3的pom配置,增加cloudera maven仓库在
repositories标签下,新增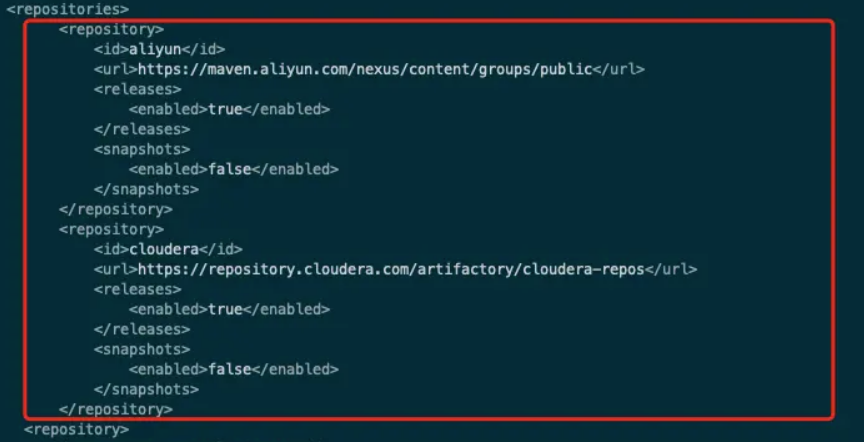
修改
/opt/mod/spark-3.3.0/pom.xml文件中的Hadoop版本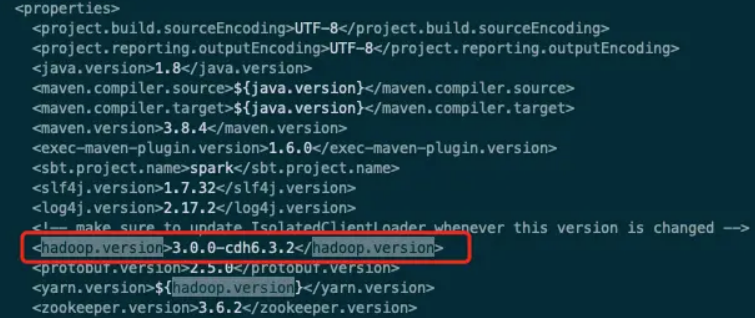
打开
make-distribution.sh修改如下内容
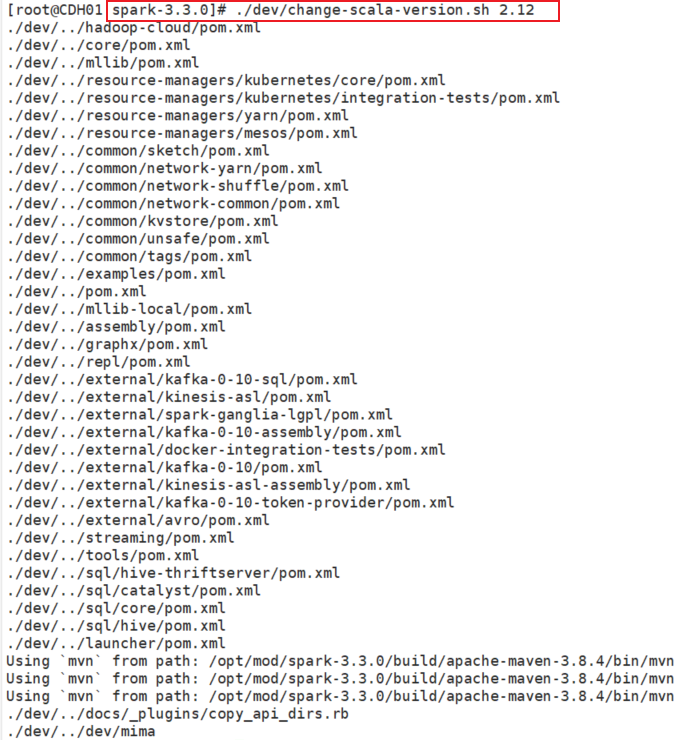
重置 scala 版本
- 这里出现下面报错的话,进入
/opt/mod/spark-3.3.0目录后再运行就好 build/mvn: 没有那个文件或目录
开始编译
用的是
spark的make-distribution.sh脚本进行编译,这个脚本其实也是用maven编译的- –tgz
- 指定以
tgz结尾
- –name
- 后面跟的是
Hadoop的版本,在后面生成的tar包带的版本号
- Pyarn
- 是基于
yarn
- Dhadoop.version=3.0.0-cdh6.3.2
- 指定
Hadoop的版本。
经过漫长的编译:
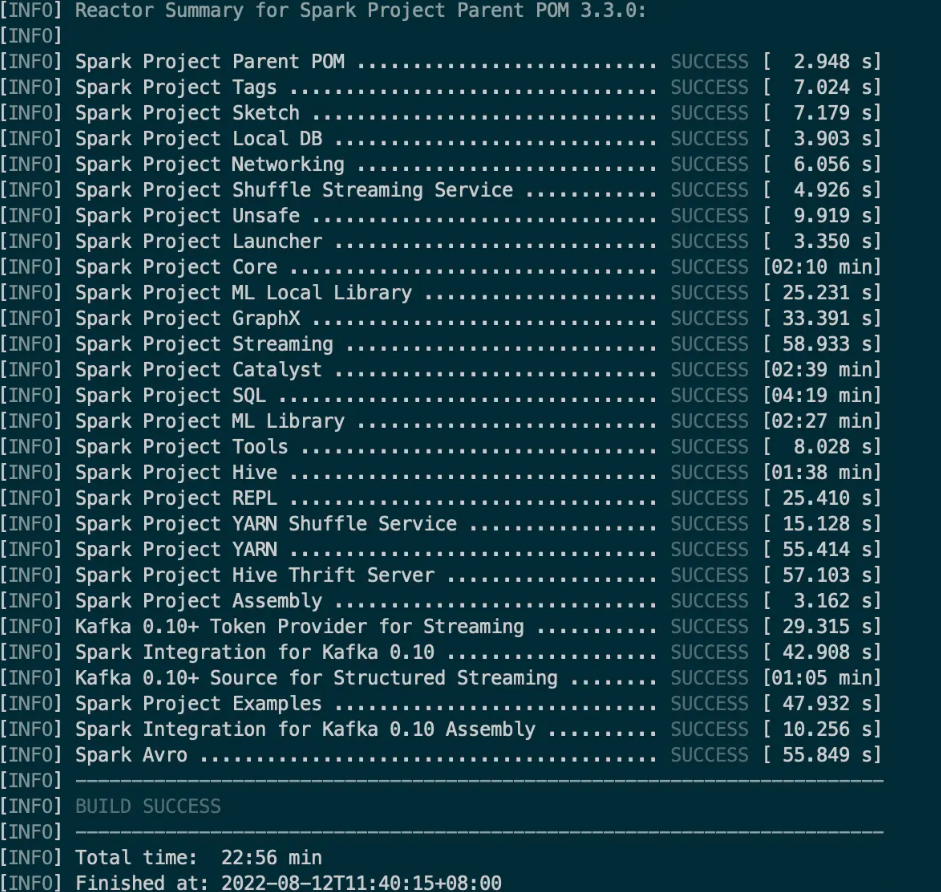
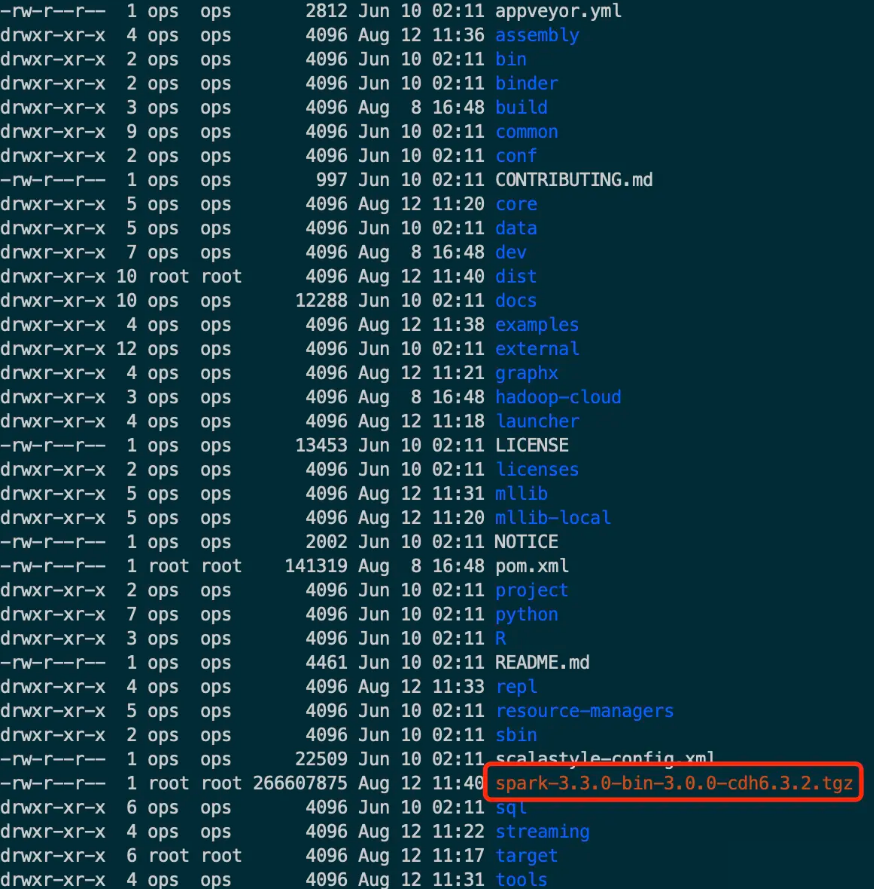
编译成功后的目录:
部署 Spark3 客户端
上传到要部署
spark3的客户端机器将 CDH 集群的
spark-env.sh复制到/opt/cloudera/parcels/CDH/lib/spark3/conf下:修改
spark-env.sh添加以下内容
将
gateway节点的hive-site.xml复制到spark3/conf目录下,不需要做变动:创建 spark-sql
创建
spark-sql文件填写以下内容
增加
spark-sql执行权限配置
spark-sql快捷方式- alternatives --install <link> <name> <path> <priority>
- install 表示安装
- link 符号链接
- name 标识符
- path 执行文件的路径
- priority 优先级
配置 conf
进入
conf目录开启日志
拷贝
spark-defaults.conf配置修改
spark-defaults.conf- 删除以下三条
- 添加
上传相关
jar包到HDFS端
创建 spark3-submit
创建
spark3-submit填写如下内容
增加
spark3-submit执行权限sh配置
spark3-submit快捷方式测试
spark3-submit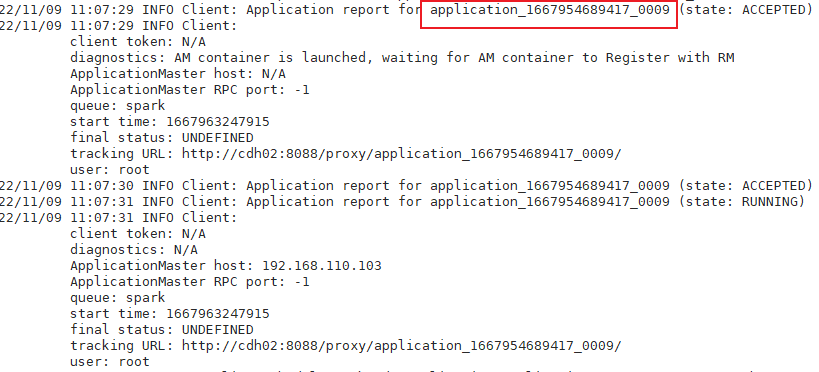
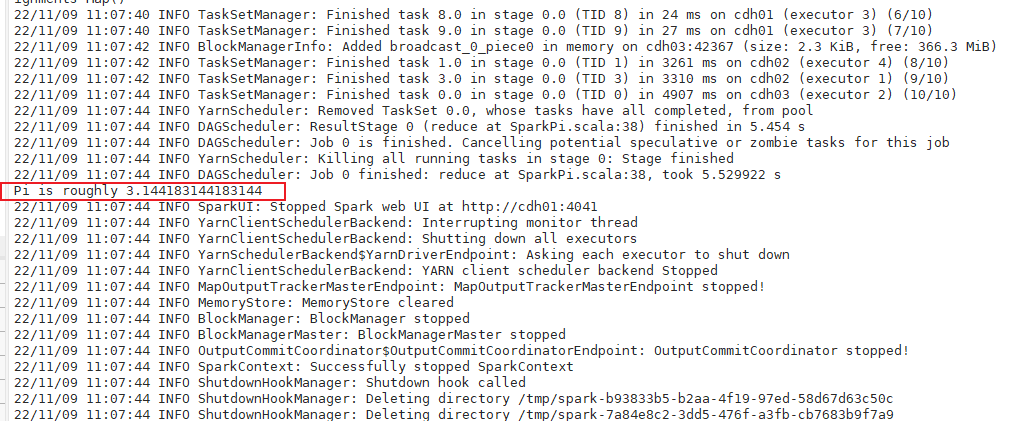
注意事项
如果有启用动态资源分配(Spark Dynamic Allocation),此时会有下列报错
需要在
spark-defaults.conf中添加useOldFetchProtocol配置这样
Hadoop集群即有了CDH版本的Spark-2.4.0又有了 apache 版本的Spark-3.3.0- 作者:PH3C
- 链接:https://notion.966699.xyz//article/CDH-Spark-3.3.0
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章