
type
status
date
summary
slug
tags
category
password
icon
报错详情
CDH集群上将Hive的默认引擎为由Mapreduce改为Spark(CDH刚搭好的时候,未优化,以MR作为引擎)进行测试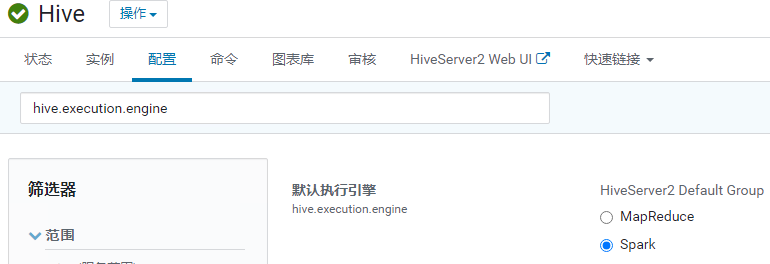
beeline启动Hive,发现Hql都 跑不了,抛错:把
Hive引擎改回Mapreduce,不报错。查看日志
在
/tmp/username目录下的hive.log日志中排错,才发现(图片为网图)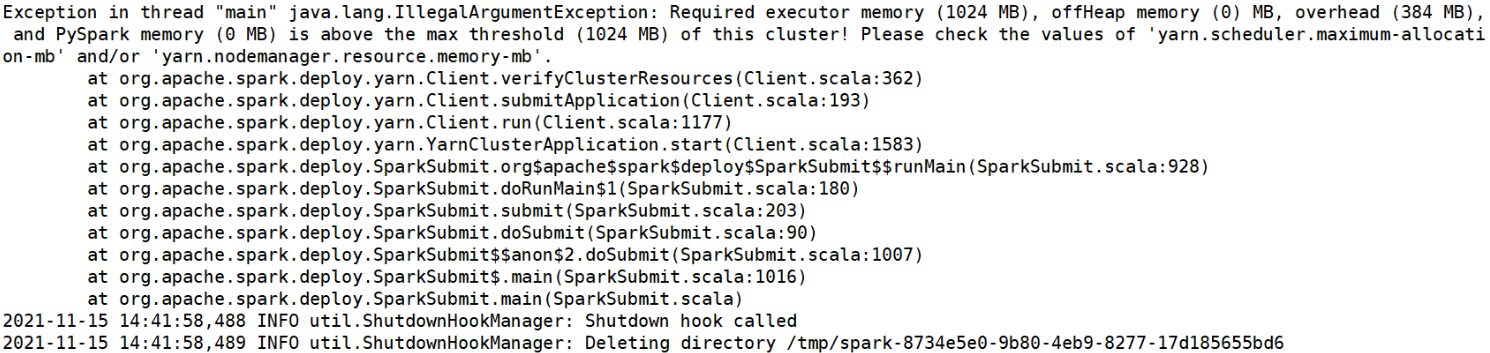
原因
这个隐藏在
Info日志中的exception才是真正报错的原因, 这就是前文提到的Yarn container的参数决定了Spark Execuotor的上下限,这里的问题是yarn.scheduler.maximum-allocation-mb使用的默认值8 GB, 小于spark.executor.memory的 10 GB,导致了Spark无法运行。
检查以下参数
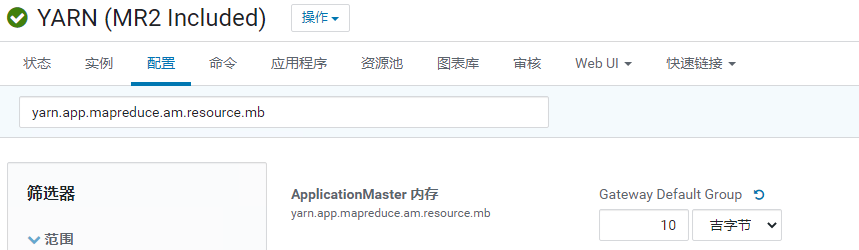
yarn.app.mapreduce.am.resource.mb
ApplicationMaster 的物理内存要求 (MiB)。
yarn.nodemanager.resource.cpu-vcores / memory-mb
单个节点上可分配的物理核数/内存总量
定义了每台
NodeManager可用的CPU定义了每台
NodeManager可用Memory- 大致的算法是保留15%-20%给系统和其他服务,保留>= 4CORE+12GRAM 左右的资源留给系统和其他服务,剩余给YARN
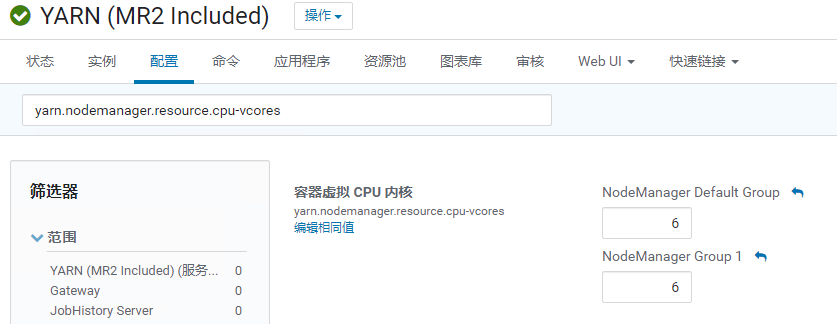
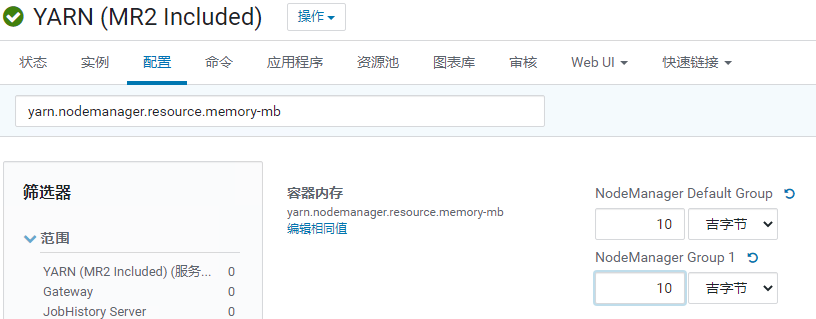
目前集群的2台
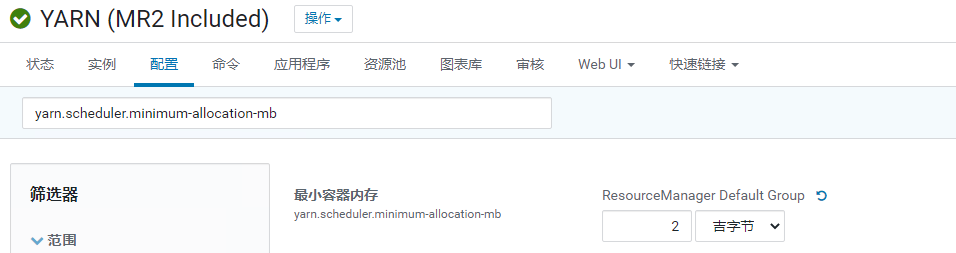
NodeManager配置为 4 Core / 14 GB:yarn.scheduler.minimum-allocation-mb
这块稍微麻烦一点,
CDH的文档没有专门的建议值,网上流行的是HDP的一个关于yarn.scheduler.minimum-allocation-mb的配置,我觉得挺有道理的Total RAM per Node | Recommended Minimum Container Size |
Less than 4 GB | 256 MB |
Between 4 GB and 8 GB | 512 MB |
Between 8 GB and 24 GB | 1024 MB |
Above 24 GB | 2048 MB |
yarn.scheduler.maximum-allocation-vcores
yarn node可使用cpu最大值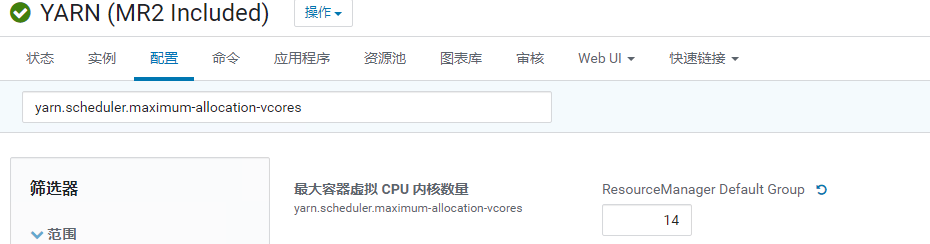
yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量
- 作者:PH3C
- 链接:https://notion.966699.xyz//article/CDH-Hive-error-Required-executor-memory
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章